


Na semana passada, as grandes empresas de IA – em teoria – aumentaram duas grandes vitórias legais. Mas as coisas não são tão diretas quanto parecem, e a lei de direitos autorais não tem sido tão emocionante desde o confronto do mês passado na Biblioteca do Congresso.
Meta
Instagram lança novos recursos de segurança para proteger adolescentes de extorsão sexual

O Instagram está introduzindo uma série de novos recursos de segurança para proteger os usuários de extorsão sexual, anunciou a empresa na quinta-feira. A empresa não permitirá mais que as pessoas façam capturas de tela ou gravações de tela de imagens ou vídeos efêmeros enviados em mensagens privadas.
Até agora, você conseguia capturar imagens de conteúdo efêmero em DMs (mensagens diretas) do Instagram, mas a outra pessoa seria notificada de que você o salvou. Com essa mudança, se você enviar uma foto ou vídeo para alguém via DMs usando os recursos “ver uma vez” ou “permitir repetição”, a outra pessoa não poderá salvar o conteúdo. Além disso, o Instagram não permitirá que as pessoas abram imagens ou vídeos “ver uma vez” ou “permitir repetição” no desktop para garantir que elas não consigam burlar as medidas de segurança.
Ao impedir que os usuários façam capturas de tela de conteúdo efêmero, o Instagram está indo um passo além do Snapchat quando se trata de garantir que o conteúdo efêmero permaneça assim. No Snapchat, se você enviar uma imagem para alguém, essa pessoa tem permissão para fazer uma captura de tela. Embora o Snapchat notifique o usuário de que sua imagem foi salva, o aplicativo não faz nada para impedir que os usuários façam capturas de tela de conteúdo efêmero em primeiro lugar.
O Instagram, por outro lado, agora está garantindo que o conteúdo que deve ser visualizado uma vez, na verdade, só possa ser visualizado uma vez.

A rede social de propriedade da Meta diz que os novos recursos anunciados hoje complementam o lançamento recente das Contas para Adolescentes , que inscrevem automaticamente usuários jovens em uma experiência de aplicativo com proteções integradas que limitam quem pode contatá-los.
Com as Contas de Adolescentes, os usuários jovens não podem receber mensagens de ninguém que não seguem ou não estão conectados, mas ainda podem receber solicitações de seguir de qualquer pessoa. Agora, o Instagram está dificultando que contas suspeitas, como as que foram criadas recentemente, solicitem seguir adolescentes.
Dependendo de quão fraudulenta uma conta pareça, o Instagram bloqueará a solicitação de seguimento completamente ou a enviará para a pasta de spam de um adolescente.

O aplicativo também está lançando avisos de segurança em DMs para avisar os adolescentes quando eles estão falando com alguém que pode morar em um país diferente. A empresa diz que está fazendo isso porque os golpistas de sextortion geralmente mentem sobre onde moram para fazer os adolescentes confiarem neles.
Como os golpistas de sextorsão costumam usar as listas de seguidores e seguidores de um adolescente para tentar chantageá-lo, o Instagram vai impedir que contas que retratam comportamento fraudulento vejam as listas de seguidores e seguidores das pessoas. Essas contas também não poderão ver quem curtiu a publicação de alguém ou ver em quais fotos foram marcadas.
Além disso, o Instagram está implementando totalmente seu recurso de proteção contra nudez globalmente após testá-lo pela primeira vez em abril . A medida de segurança desfoca automaticamente imagens que contêm nudez em DMs. O recurso será habilitado por padrão para usuários adolescentes. Quanto às pessoas que as enviam, o Instagram as avisará sobre os riscos envolvidos no envio de fotos privadas.

Para fornecer mais suporte em seu aplicativo, o Instagram está fazendo uma parceria com a Crisis Text Line nos EUA. Agora, quando um usuário relata um problema relacionado à segurança infantil ou sextorsão, ele verá uma opção para falar com um conselheiro de crise.
As mudanças acontecem dez meses depois que o Instagram, assim como outras grandes redes sociais, foi criticado por legisladores por não fazer o suficiente para proteger os usuários jovens em sua plataforma.
Como parte de seus esforços para combater a sextorsão, o Instagram vai começar a mostrar aos usuários um vídeo educativo sobre golpistas de sextorsão para adolescentes nos EUA, Reino Unido, Austrália e Canadá. A rede social também está fazendo parcerias com influenciadores como Bella Poarch e Brent Rivera para criar conteúdo sobre como identificar sextorsão e o que fazer se isso acontecer.
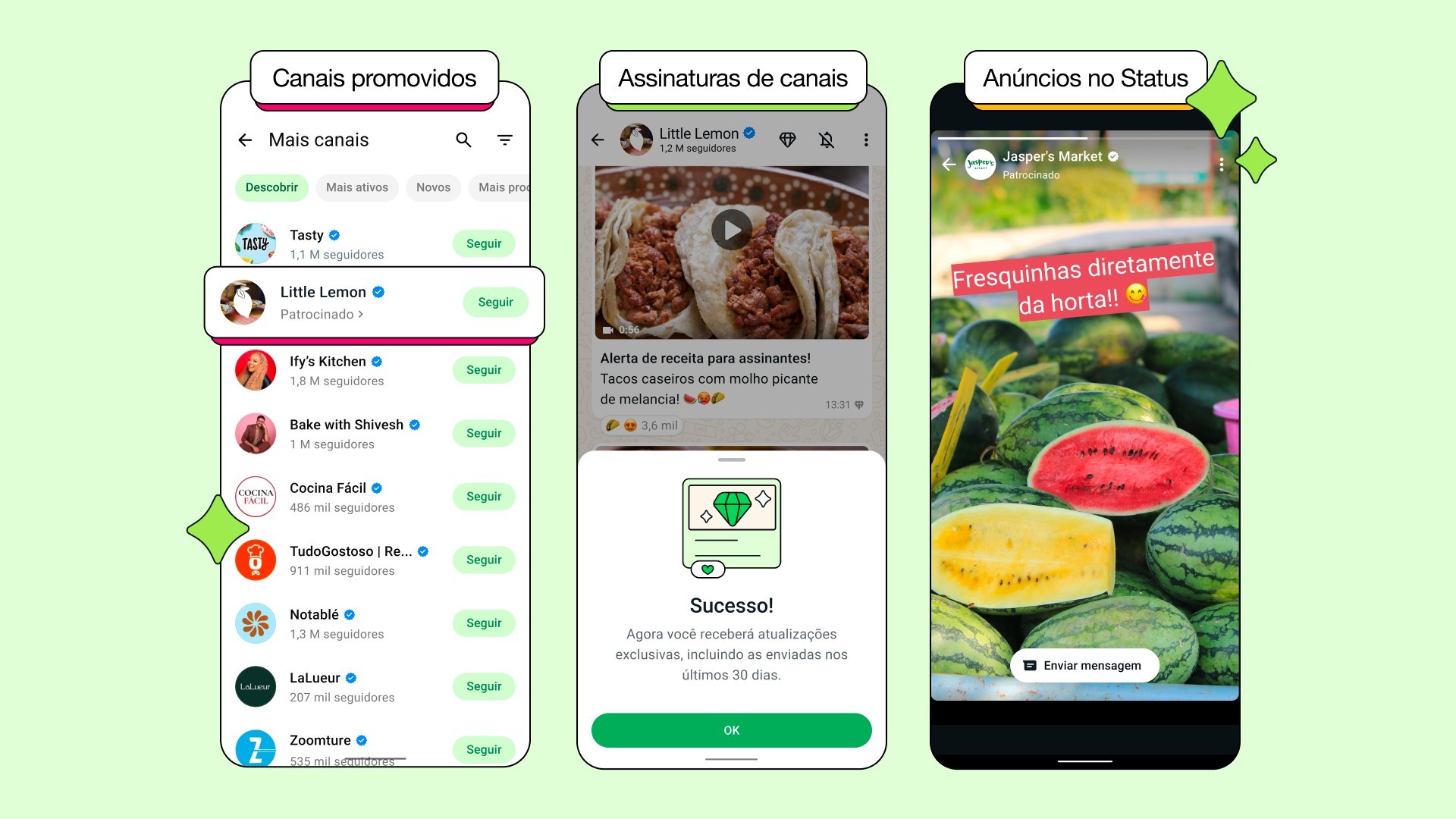
Propaganda vai aparecer no Status, área parecida com o Stories do Instagram. Segundo a plataforma, conversas não serão usadas para direcionar anúncios.
Onde vão aparecer os anúncios no Whatsapp?
O WhatsApp vai exibir anúncios no Status, área parecida com o Stories do Instagram. Além disso, canais poderão cobrar usuários por acesso a conteúdo exclusivo e pagar para terem mais destaque nas sugestões do aplicativo.
As mudanças se concentram na aba “Atualizações” e começam a ser liberadas nesta segunda-feira (16). Não haverá anúncios na aba “Conversas” e, segundo o WhatsApp, suas mensagens não serão usadas para direcionar propaganda.
O chefe global do WhatsApp, Will Cathcart, afirmou em entrevista exclusiva ao g1 que a plataforma quer garantir a todos que nada mudará em relação à privacidade e que o conteúdo compartilhado por usuários continuará sendo protegido por criptografia.
Ainda de acordo com o WhatsApp, seu número de telefone nunca será vendido ou compartilhado com anunciantes.
“Não podemos segmentar anúncios com base no que você diz ou em quais amigos você envia mensagens. Os anúncios serão baseados em como você usa a aba ‘Atualizações'”, afirmou.
Dos 3 bilhões de usuários em todo o mundo, 1,5 bilhão acessam a aba “Atualizações” diariamente, segundo o WhatsApp. A plataforma diz que os anúncios devem ajudar empresas e canais a chegaram num público maior.
“Há muitas empresas pequenas que não têm site ou aplicativo. Elas usam o WhatsApp para se comunicar com clientes”, disse Cathcart. “Queremos dar a elas a opção de alcançar pessoas que não estão em sua rede”.
Como serão os anúncios no WhatsApp
A propaganda no WhatsApp vai aparecer para quem acessa o que contatos postam no Status, que fica na aba “Atualizações”. O aplicativo mostrará conteúdo de empresas entre essas publicações.
Apesar de não saber o que você fala no aplicativo, o WhatsApp pode identificar quais são seus interesses a partir dos canais que você segue e em como você vai interagir com anúncios.
A propaganda também poderá considerar informações técnicas, como o modelo do seu celular, o tipo da sua conexão à internet e a sua localização geral (por exemplo, cidade e país, e não o endereço exato).
Outra fonte de informações sobre usuários é a Central de Contas, usada para integrar perfis de plataformas da Meta (Instagram, Facebook e WhatsApp). Se você tem essa opção ativada, o aplicativo usará dados das suas outras contas para direcionar anúncios.
Conteúdo pago em canais
O recurso de conteúdo pago em canais será liberado para um grupo selecionado antes de ficar disponível para todos.
Os administradores poderão definir os preços das assinaturas por conteúdo exclusivo nos canais. O pagamento será feito nas lojas de aplicativos do Google e da Apple, que cobram comissão por transações.
“Administradores estão expandindo seus canais e pensam neles como um negócio”, disse Cathcart. “Queremos oferecer mais ferramentas e, para alguns criadores de canais, a assinatura paga fará sentido”.
O WhatsApp tem regras contra conteúdo ilegal em canais. Com as assinaturas pagas, o aplicativo precisará evitar se tornar uma fonte de renda para quem compartilha esse tipo de material.
Segundo o chefe global do WhatsApp, a plataforma terá processos para garantir que administradores estejam de acordo com suas políticas. “Trabalharemos arduamente para tentar impedir que alguém faça uso indevido do sistema”, afirmou.
Clique para ler matéria original

Primeiro, o juiz William Alsup decidiu que era um uso justo para antropia treinar em uma série de livros de autores. Então, o juiz Vince Chhabria negou provimento a outro grupo de queixa dos autores contra a meta para treinamento deles livros. No entanto, longe de resolver os enigmas legais em torno da IA moderna, essas decisões podem ter acabado de tornar as coisas ainda mais complicadas.
Ambos os casos são de fato vitórias qualificadas para meta e antropia. E pelo menos um juiz – Alsup – parece simpático a alguns dos principais argumentos da indústria de IA sobre direitos autorais. Mas essa mesma decisão criticou o uso da mídia pirata pela startup, deixando -a potencialmente no gancho por danos financeiros maciços. (Antrópica até admitiu que não adquiriu inicialmente uma cópia de todos os livros que usava.) Enquanto isso, a meta decisão afirmou que, como uma inundação de conteúdo de IA poderia copiar artistas humanos, todo o campo de treinamento do sistema de IA pode estar fundamentalmente em desacordo com uso justo. E nenhum dos casos abordou uma das maiores questões sobre a IA generativa: quando é o seu saída infringem direitos autorais e quem está no gancho, se o fizer?
Alsup e Chhabria (aliás no distrito norte da Califórnia) estavam decidindo sobre conjuntos de fatos relativamente semelhantes. Meta e antropia ambos enormes coleções piratas de livros protegidos por direitos autorais para criar um conjunto de dados de treinamento para seus grandes modelos de idiomas e Claude. Mais tarde, Anthropic fez uma volta e começou a comprar legalmente livros, rasgando as cobertas para “destruir” a cópia original e examinando o texto.
Os autores argumentaram que, além da pirataria inicial, o processo de treinamento constituía um uso ilegal e não autorizado de seu trabalho. Meta e antropia rebateram que essa construção de banco de dados e o treinamento de LLM constituíam uso justo.
Ambos os juízes concordaram basicamente que os LLMs atendem a um requisito central para uso justo: eles transformam o material de origem em algo novo. Alsup chamou o uso de livros para treinar Claude de “extremamente transformador”, e Chhabria concluiu “não há como disputa” o valor transformador da llama. Outra grande consideração para uso justo é o impacto do novo trabalho em um mercado para o antigo. Ambos os juízes também concordaram que, com base nos argumentos apresentados pelos autores, o impacto não foi grave o suficiente para inclinar a escala.
Adicione essas coisas juntas, e as conclusões foram óbvias … mas apenas No contexto desses casos, e no caso de Meta, porque os autores pressionaram uma estratégia legal que seu juiz achou totalmente inepto.
Coloque desta maneira: quando um juiz diz que sua decisão “não representa a proposição de que o uso de materiais protegidos por direitos autorais para treinar seus modelos de idiomas é lícito” e “mantém apenas a proposição que esses demandantes fizeram os argumentos errados e falharam em desenvolver um recorde em apoio à direita” – como a Chhabria fez – a IA Prospects das empresas de futuras lutas com ele se destacou.
Ambas as decisões foram tratadas especificamente com o treinamento – ou a mídia sendo alimentada nos modelos – e não alcançou a questão da saída LLM, ou os modelos de coisas produzem em resposta aos avisos do usuário. Mas a produção é, de fato, extremamente pertinente. Uma enorme luta legal entre The New York Times e o OpenAI começou em parte com a alegação de que o chatgpt poderia verbatim regurgitar grandes seções de Vezes histórias. A Disney processou recentemente o Midjourney pela premissa de que “gerará, exibirá publicamente e distribuirá vídeos com os personagens protegidos por direitos autorais da Disney e da Universal” com uma ferramenta de vídeo recém -lançada. Mesmo em casos pendentes que não estavam focados na produção, os demandantes podem adaptar suas estratégias se agora acharem uma aposta melhor.
Os autores do caso antrópico não alegaram que Claude estava produzindo uma saída diretamente violando. Os autores do meta caso argumentaram que Llama, mas não conseguiu convencer o juiz – que descobriu que isso não cuspiria mais do que cerca de 50 palavras de qualquer trabalho. Como Alsup observou, lidar puramente com entradas mudou os cálculos drasticamente. “Se as saídas vistas pelos usuários estivessem violando, os autores teriam um caso diferente”, escreveu o ALSUP. “E, se os resultados se tornarem infratores, os autores poderiam trazer esse caso. Mas esse não é esse caso.”
Na sua forma atual, os principais produtos generativos de IA são basicamente inúteis sem saída. E não temos uma boa imagem da lei em torno dela, especialmente porque o uso justo é uma defesa idiossincrática e caso a caso que pode se aplicar de maneira diferente a mídias como música, arte visual e texto. A antropia é capaz de digitalizar livros de autores nos fala muito pouco sobre se o Midjourney pode ajudar legalmente as pessoas a produzir memes de minions.
Lacaios e New York Times Os artigos são exemplos de cópia direta na saída. Mas a decisão de Chhabria é particularmente interessante porque torna a questão da saída muito, muito mais ampla. Embora ele possa ter decidido a favor da meta, toda a abertura de Chhabria argumenta que os sistemas de IA são tão prejudiciais para artistas e escritores que seus danos superam qualquer possível valor transformador – basicamente, porque são máquinas de spam.
A IA generativa tem o potencial de inundar o mercado com quantidades infinitas de imagens, músicas, artigos, livros e muito mais. As pessoas podem levar os modelos generativos de IA a produzir essas saídas usando uma pequena fração do tempo e da criatividade que, de outra forma, seriam necessários. Assim, treinando modelos generativos de IA com obras protegidas por direitos autorais, as empresas estão criando algo que frequentemente minará dramaticamente o mercado para esses trabalhos e, portanto, minará dramaticamente o incentivo para os seres humanos criarem coisas da maneira antiquada.
…
Como a Suprema Corte enfatizou, o inquérito de uso justo depende de fatos e existem poucas regras de linha brilhante. Certamente não há regra de que, quando o uso de um trabalho protegido é “transformador”, isso inocula automaticamente você de uma reivindicação de violação de direitos autorais. E aqui, copiar os trabalhos protegidos, por mais transformadores que seja, envolve a criação de um produto com a capacidade de prejudicar gravemente o mercado para as obras que estão sendo copiadas e, portanto, minam severamente o incentivo para os seres humanos criarem.
…
O resultado é que, em muitas circunstâncias, será ilegal copiar trabalhos protegidos por direitos autorais para treinar modelos generativos de IA sem permissão. O que significa que as empresas, para evitar a responsabilidade pela violação de direitos autorais, geralmente precisam pagar aos detentores de direitos autorais pelo direito de usar seus materiais.
E garoto, isso claro Seria interessante se alguém processaria e fizesse esse caso. Depois de dizer que “no grande esquema das coisas, as consequências dessa decisão são limitadas”, Chhabria observou que essa decisão afeta apenas 13 autores, não os “inúmeros outros” cujo trabalho meta usou. Infelizmente, uma opinião judicial escrita é incapaz de transmitir fisicamente uma piscadela e um aceno de cabeça.
Esses processos podem estar longe no futuro. E Alsup, embora ele não estivesse confrontado com o tipo de argumento que Chhabria sugeriu, parecia potencialmente antipático a isso. “A queixa dos autores não é diferente do que seria se eles se queixassem de que o treinamento de crianças em idade escolar para escrever bem resultaria em uma explosão de obras concorrentes”, escreveu ele sobre os autores que processaram o Antrópico. “Este não é o tipo de deslocamento competitivo ou criativo que diz respeito à Lei dos Direitos Autorais. A Lei procura promover obras de autoria originais, não proteger os autores contra a concorrência”. Ele também desprezou a alegação de que os autores estavam sendo privados de taxas de licenciamento para treinamento: “um mercado”, ele escreveu, “não é um que a Lei de Direitos Autorais autorize os autores a explorar”.
Mas mesmo a decisão aparentemente positiva de Alsup tem uma pílula venenosa para as empresas de IA. Treinamento em adquirido legalmente O material, ele decidiu, é um uso justo clássico protegido. Treinamento em pirateado O material é uma história diferente, e Alsup absolutamente exoria qualquer tentativa de dizer que não é.
“Esta ordem duvida que qualquer infrator acusado possa cumprir seu ônus de explicar por que o download de cópias de origem de sites piratas que poderia ter comprado ou acessado legalmente era razoavelmente necessário para qualquer uso justo subsequente”, escreveu ele. Havia muitas maneiras de digitalizar ou copiar livros adquiridos legalmente (incluindo o próprio sistema de varredura da Anthropic), mas “antropia não fez essas coisas – em vez disso, roubou os trabalhos para sua biblioteca central, baixando -os de bibliotecas piratas”. Eventualmente, a mudança para a digitalização de livros não apaga o pecado original e, de certa forma, ele realmente o compõe, porque demonstra que o Antrópico poderia ter feito as coisas legalmente desde o início.
Se novas empresas de IA adotarem essa perspectiva, elas terão que construir em custos de inicialização extras, mas não necessariamente arruinados. Há o preço inicial da compra do que antropia em um ponto descrito como “todos os livros do mundo”, além de qualquer mídia necessária para coisas como imagens ou vídeo. E no caso do antropic, estes foram físico Trabalhos, porque as cópias impressas da mídia evitam os tipos de DRM e acordos de licenciamento que os editores podem colocar nos digitais – então adicione algum custo extra para o trabalho de digitalizá -los.
Mas praticamente qualquer grande jogador de IA atualmente opera é conhecido ou suspeito de ter treinado em livros baixados ilegalmente e outras mídias. Antrópico e os autores irão ser julgados para matar as acusações diretas de pirataria e, dependendo do que acontecer, muitas empresas podem estar hipoteticamente em risco de danos financeiros quase inestimáveis - não apenas de autores, mas de qualquer pessoa que demonstre seu trabalho foi adquirida ilegalmente. Como especialista jurídico Blake Reid coloca vividamente“Se há evidências de que um engenheiro estava torrentando um monte de coisas com a bênção C-Suite, transforma a empresa em uma piñata de dinheiro”.
Além de tudo isso, os muitos detalhes inquietos podem facilitar a falta do mistério maior: como essa disputa legal afetará a indústria da IA e as artes.
Ecoando um argumento comum entre os proponentes da IA, o ex -executivo da Meta Nick Clegg disse recentemente que obter a permissão dos artistas para o treinamento de dados “basicamente mataria a indústria da IA”. Essa é uma reivindicação extrema, e dado que todas as empresas de licenciamento já estão impressionantes (inclusive com a Vox Media, a empresa controladora da A beira), parece cada vez mais duvidoso. Mesmo que sejam confrontados com penalidades de pirataria graças à decisão da Alsup, as maiores empresas de IA têm bilhões de dólares em investimento – elas podem resistir muito. Mas menores, particularmente jogadores de código aberto podem ser muito mais vulneráveis, e muitos deles são também quase certamente treinado em obras piratas.
Enquanto isso, se a teoria de Chhabria estiver certa, os artistas poderiam colher uma recompensa por fornecer dados de treinamento aos gigantes da IA. Mas é altamente improvável que as taxas encerrassem esses serviços. Isso ainda nos deixaria em uma paisagem cheia de spam, sem espaço para futuros artistas.
O dinheiro nos bolsos dos artistas desta geração pode compensar o brighting do próximo? A lei de direitos autorais é a ferramenta certa para proteger o futuro? E que papel os tribunais devem desempenhar em tudo isso? Essas duas decisões entregaram vitórias parciais à indústria da IA, mas deixam muito mais questões muito maiores sem resposta.

Em um movimento que promete revolucionar a criação de conteúdo digital, a Meta lançou o NotebookLlama, uma implementação aberta do popular recurso de geração de podcasts do Google, conhecido como NotebookLM. Utilizando os modelos Llama da própria Meta, essa nova ferramenta visa democratizar a produção de podcasts, permitindo que qualquer pessoa, desde criadores independentes até empresas, transforme textos em áudios dinâmicos e envolventes.
O Que É o NotebookLlama?

O NotebookLlama é uma plataforma que permite a geração de podcasts a partir de arquivos de texto, como PDFs de artigos de notícias ou postagens de blogs. O processo começa com a criação de uma transcrição do texto enviado. Em seguida, a ferramenta adiciona dramatizações e interrupções, antes de utilizar modelos de texto-para-fala para produzir o áudio final. Essa abordagem visa criar uma experiência de escuta mais rica e envolvente, semelhante ao que os ouvintes esperam de um podcast profissional.
Qualidade de Áudio e Desafios
Apesar de suas promessas, os resultados do NotebookLlama ainda deixam a desejar em comparação com o NotebookLM. As amostras de áudio geradas apresentam uma qualidade bastante robótica, com vozes que frequentemente se sobrepõem de maneira estranha. Os pesquisadores da Meta reconhecem que a qualidade do modelo de texto-para-fala é um fator limitante e afirmam que melhorias são necessárias para tornar o som mais natural.
Em sua página no GitHub, a equipe do NotebookLlama destacou que uma abordagem alternativa poderia envolver a criação de diálogos entre dois agentes, debatendo um tópico de interesse, o que poderia enriquecer ainda mais o conteúdo gerado. No entanto, atualmente, a ferramenta utiliza um único modelo para elaborar o esboço do podcast.
O Problema da “Alucinação”
Um dos desafios persistentes enfrentados por projetos de IA, incluindo o NotebookLlama, é o fenômeno conhecido como “alucinação”. Isso se refere à tendência dos modelos de linguagem de gerar informações imprecisas ou completamente inventadas. Assim, mesmo que o NotebookLlama ofereça uma nova maneira de criar conteúdo, os ouvintes devem estar cientes de que os podcasts gerados por IA podem conter dados fictícios.
O Futuro do Podcasting com IA
O lançamento do NotebookLlama representa um passo significativo na evolução do podcasting, permitindo que mais vozes sejam ouvidas e que a criação de conteúdo se torne mais acessível. À medida que a tecnologia avança e os modelos de IA se tornam mais sofisticados, podemos esperar melhorias na qualidade do áudio e na precisão das informações geradas.
Com o NotebookLlama, a Meta não apenas abre novas possibilidades para criadores de conteúdo, mas também convida todos a explorar o potencial da inteligência artificial na narrativa digital. É um momento emocionante para o podcasting, onde a inovação e a criatividade se encontram, e onde cada um de nós pode se tornar um contador de histórias.


Negócios1 ano
‘Estou sendo paga para corrigir problemas causados por IA’

Microsoft1 ano
Microsoft vai cortar até 9.000 empregos, pois investe em IA

Negócios1 ano
OpenAI ganha contrato de R$ 1 trilhão e fornecerá sistemas de inteligência artificial para a Defesa dos EUA

Audiohá 2 anos
Meta Lança NotebookLlama: A Nova Alternativa do Podcasting com IA

Criatividadehá 2 anos
Arcade AI: A Revolução na Criação de Joias Personalizadas com IA

Criatividadehá 2 anos
Google, Microsoft e Perplexity promovem racismo científico em resultados de pesquisa de IA
-
 Audiohá 2 anos
Audiohá 2 anosMeta Lança NotebookLlama: A Nova Alternativa do Podcasting com IA
-
 Criatividadehá 2 anos
Criatividadehá 2 anosArcade AI: A Revolução na Criação de Joias Personalizadas com IA
-
 Criatividadehá 2 anos
Criatividadehá 2 anosGoogle, Microsoft e Perplexity promovem racismo científico em resultados de pesquisa de IA
-

 Applehá 2 anos
Applehá 2 anosApple Intelligence: Tudo o que Você Precisa Saber Sobre o Lançamento!
-

 Tecnologia1 ano
Tecnologia1 anoAs emissões do Google subiram 51%, pois a demanda de eletricidade da IA inviabiliza os esforços para ficar verde | Google
-

 Apps1 ano
Apps1 anoWhatsApp terá anúncios e canais com conteúdo pago; veja como vai funcionar
-

 Criatividadehá 2 anos
Criatividadehá 2 anosA IA Claude da Anthropic agora pode executar e escrever código
-

 Appshá 2 anos
Appshá 2 anosO e-mail da Notion está próximo do lançamento